Overview
ntrp keeps memory in layers instead of treating every extracted sentence as always-visible profile context.- Facts are the source-of-truth records extracted from chats, tools, and connected sources.
- Patterns are derived summaries over facts. In the API they are still called
observations, but the UI calls them patterns because they are not raw truth. - Profile entries are the only always-visible memory surface. They are curated, budgeted, and backed by direct fact or pattern provenance.
- Learning proposals are review-gated policy, prompt, skill, automation, or memory improvements. They never auto-apply silently.
Facts
Facts are durable evidence records. They carry text, source metadata, timestamps, entities, embeddings, access counts, and lifecycle state. Facts should answer: “what concrete thing did ntrp observe or store?” Examples:- “The user prefers direct engineering feedback.”
- “The Dex automation table mutation issue was discussed on May 1, 2026.”
- “A calendar event named
morning briefingruns daily at 08:00.”
Patterns
Patterns are derived context built from supporting facts. They compress repeated or related evidence into a higher-level statement. Patterns should answer: “what trend, repeated behavior, or durable relationship is supported by multiple facts?” Examples:- “The user tends to reject broad agent abstractions unless the data flow becomes simpler.”
- “Recent backend work focused on reducing tool-schema prompt cost through deferred loading.”
Profile Entries
Profile entries are curated core memory shown to the agent by default. They should stay small and directly useful across unrelated sessions. Profile entries should answer: “what should the agent almost always know before responding?” Good profile entries:- Stable identity, preference, relationship, or standing constraint.
- Short enough to fit in the always-on memory budget.
- Backed by source fact ids or pattern ids.
- One-off tasks, current debugging state, temporary plans, or raw extracted facts.
- Generated summaries without direct provenance.
- Large biographies or project dumps.
Write Path
When ntrp learns something new:- Extract durable source facts from user-visible evidence.
- Embed and index facts for semantic and full-text retrieval.
- Link entities and provenance.
- Consolidate facts into patterns when there is enough support.
- Propose profile or policy changes when memory feedback suggests a durable improvement.
Consolidation
Consolidation runs as a builtin automation with dual triggers: periodically and after idle time. It performs narrow jobs:- merge near-duplicate facts
- update or create supported patterns
- archive stale low-value records after dry-run review
- repair stale search indexes and missing embeddings
- record audit events for memory writes and automation outcomes
Retrieval
For each prompt, ntrp combines:- profile entries that are always-on and budgeted
- query-specific memory prefetch from facts and patterns
- access telemetry showing which memory was retrieved, injected, omitted, or later corrected
Continual Learning
The learning loop observes explicit feedback and runtime evidence, then creates reviewable proposals. Current lanes include:- memory: extraction, profile, compression, or cleanup policy notes
- prompt: bounded runtime prompt notes
- skill: proposed procedural skill improvements
- automation: automation scheduling or prompt behavior notes
Desktop Memory UI
Open the Memory view in the desktop app to inspect and control memory.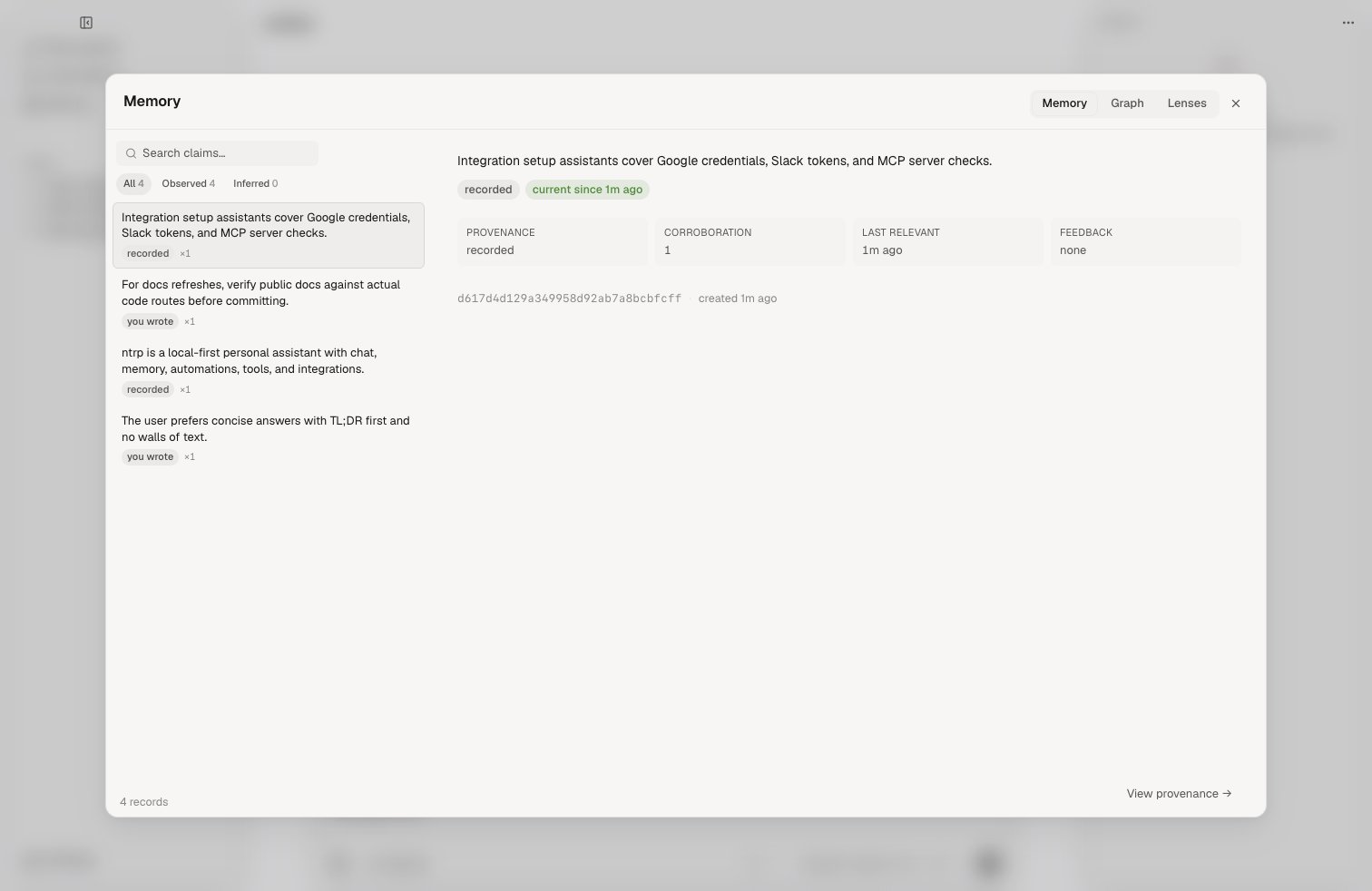
- Memory: search and inspect durable records, provenance, corroboration, feedback, and record lifecycle state.
- Graph: inspect linked records and relationships visually.
- Lenses: create curated views over memory by naming a criterion and reviewing the rendered claims.
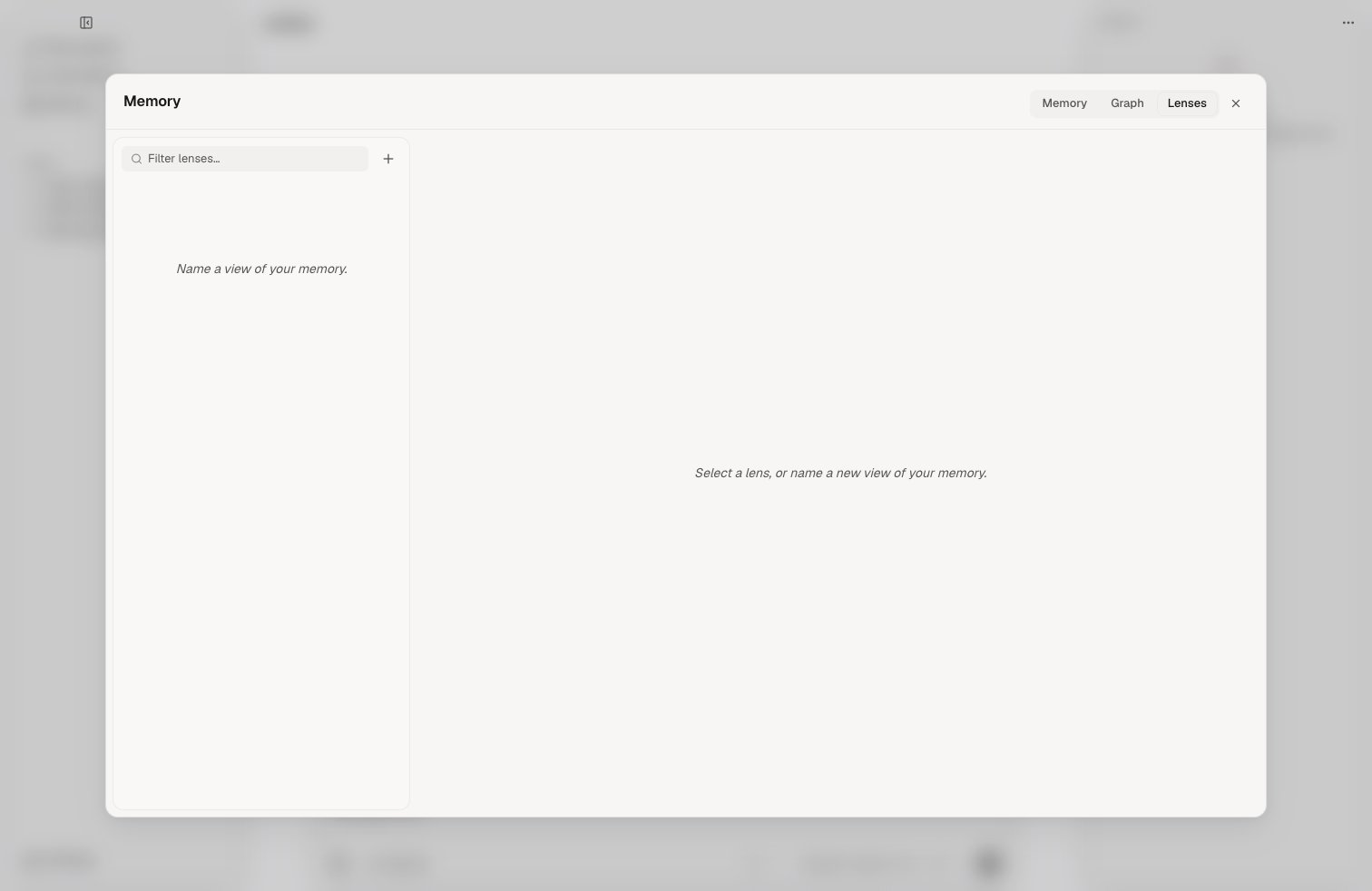
Agent Tools
remember: store a durable fact with approvalrecall: search facts and patternsforget: delete or archive matching memory with approval